Media Summary: Another session in a series of tutorials for the NCAR and university research communities featuring Jiri Kraus of As neural networks get deeper and training data get bigger, deep learning needs more Dive into Deep Learning UC Berkeley, STAT 157 Slides are at The book is at
Overview
Lecture 64 Multi Gpu Programming - Detailed Analysis
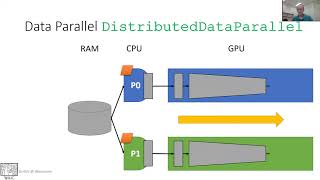
Another session in a series of tutorials for the NCAR and university research communities featuring Jiri Kraus of As neural networks get deeper and training data get bigger, deep learning needs more Dive into Deep Learning UC Berkeley, STAT 157 Slides are at The book is at Mode Parallel, Gradient Accumulation, Data Parallel with PyTorch, Larger Batches In the third video of this series, Suraj Subramanian walks through the code required to implement distributed training with DDP on ... Adam Grzywaczewski and Adolf Hohl hold are two session webinar "
Speakers: William Brandon (Anthropic) and Simran Arora (ThunderKittens) Full Schedule: The
Gallery
Photo Gallery











Related

![Lecture 75 [ScaleML Series] GPU Programming Fundamentals + ThunderKittens](https://i.ytimg.com/vi/Cl2B_hmg4gA/mqdefault.jpg)